Review Article - (2025) Volume 6, Issue 1
The advent of machine learning algorithms has put a treat in fake news in 21st century. Today, technology has proved that any information that are put on internet will be scrutinize in other to ascertain the authenticity of the information. This fake news can be a derogatory message against country, organization, individual, society and political parties because its fake news and it can be in any form. Today, there are many social media, platforms that many users can post uncensored messages without authenticity and as a results any user can make a post or spread the news through these online platforms. These platforms do not embed any of the machine learning classifiers to verify their posts as a result this research will use machine learning classifiers that can detect this fake news automatically and the use of machine learning classifiers for detecting the fake news is described in the literature review.
Text classification • Online fake news • Social media • Machine learning classifiers • Model
The proliferation of fake news, facilitated by social media platforms, has posed substantial challenges to the integrity of information dissemination. This misinformation can influence public opinion, affect elections and lead to social unrest. For instance, during the 2016 U.S. presidential election, fake news stories spread widely on social media, influencing voter perceptions and potentially the election outcome. Traditional methods of fake news detection, primarily relying on manual verification, are insufficient due to the sheer volume of content generated daily. This manual verification process is time-consuming and requires significant human resources, making it impractical for real-time detection.
Automated fake news detection using advanced NLP techniques has become essential to address this challenge. NLP provides tools and methods to process and analyze large volumes of text data quickly and accurately. Early approaches to fake news detection employed basic text classification techniques using machine learning algorithms such as Naive Bayes, Support Vector Machines (SVM) and decision trees. These methods typically rely on handcrafted features, including linguistic and lexical patterns, to identify deceptive content. However, they often struggle with the complexity and variability of language used in fake news [1].
Recent advances in NLP, particularly the development of transformer models like Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-trained Transformer (GPT), have shown great promise in understanding and processing human language more effectively. These models use deep learning techniques to capture contextual information from text, enabling more accurate and nuanced analysis. BERT, for example, uses a bidirectional approach to read the entire sequence of wordsat once, providing a deeper understanding of language context compared to unidirectional models. GPT, on the other hand, generates human-like text by predicting the next word in a sequence, making it useful for generating synthetic news articles and detecting inconsistencies.
This paper explores the use of these advanced NLP techniques to enhance the accuracy of fake news detection. We propose a hybrid approach that combines the strengths of transformer models with traditional machine learning algorithms, aiming to leverage the contextual understanding of transformers and the robustness of classifiers like SVM. By integrating these methods, we aim to improve the precision and recall rates of fake news detection systems, making them more reliable and effective in real-world applications [2].
Related works
Previous research has focused on various techniques for fake news detection, including linguistic analysis, machine learning algorithms and neural networks. Methods such as Naive Bayes, Support Vector Machines (SVM) and decision trees have been widely used. However, recent advances in NLP, particularly the development of transformer models like BERT and GPT, have shown great promise in understanding and processing human language more effectively.
Linguistic analysis approaches typically involve analyzing the textual content of news articles to identify stylistic and lexical patterns that are indicative of deception. These methods often use features such as word frequencies, part-of-speech tags and syntactic structures. Machine learning algorithms, on the other hand, learn from labeled datasets to classify news articles as real or fake based on these features.
Neural network-based approaches have also gained popularity due to their ability to learn complex patterns from large datasets. Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) have been used to capture the temporal and spatial dependencies in text data. However, these models often require significant computational resources and large amounts of labeled data for training [3].
The advent of transformer models like BERT and GPT has revolutionized the field of NLP. These models use self-attention mechanisms to capture long-range dependencies in text, allowing them to understand the context and semantics of words more effectively. BERT, in particular, has achieved state-of-the-art performance on various NLP tasks by using a bidirectional approach to encode the context of words. GPT, on the other hand, has shown impressive results in text generation and language modeling tasks.
Data collection
LIAR dataset: This dataset contains 12,836 human-labeled short statements from Politifact.com, categorized into six labels: Pantsfire, false, barely-true, half-true, mostly-true and true.
FA-KES dataset: A multilingual dataset with real and fake news articles, providing a variety of sources and perspectives).
Fake news net dataset: This dataset includes news content, social context and spatiotemporal information, offering a comprehensive resource for studying fake news detection.
Pre-processing
Preprocessing steps include tokenization, stop word removal, stemming and lemmatization. Additionally, we convert text data into numerical format using techniques like Term Frequency-Inverse Document Frequency (TF-IDF) and word embedding’s [4].
Tokenization: Splitting text into individual words or tokens.
Stop word removal: Removing common words that do not contribute to meaning (e.g. "and," "the").
Stemming and lemmatization: Reducing words to their base or root form.
Numerical representation: Using TF-IDF and word embedding’s to convert text into numerical format.
Model architecture
The propose of a hybrid model that integrates transformer models with traditional machine learning algorithms. Our approach involves fine-tuning a pre-trained BERT model to extract contextual features from the text. These features are then fed into a machine learning classifier, such as an SVM or a random forest, to make the final prediction.
BERT model
BERT, developed by Google, is designed to understand the context of a word in search queries. BERT uses a bidirectional approach by reading the entire sequence of words at once, providing a deeper understanding of language context compared to unidirectional models. Mathematically, BERT uses the following transformation for encoding:
ht=Transformer (Et)
Where ht represents the hidden state at position t1, and Et represents the input embedding at position t.
The objective function for BERT's masked language model is:
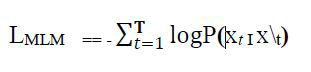
Where T is the number of tokens, xt is the masked token and x\t represents the sequence with the masked token.
Support Vector Machines (SVM) classifier
Support vector machines are effective in high-dimensional spaces and used for classification tasks. The decision boundary is defined by the following optimization problem:
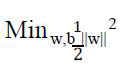
Subject to y1(w • x1 + b) ≥ 1, i = 1, . . . , n
Where w is the weight vector, b is the bias, yi is the label and xi is the feature vector.
The SVM aims to maximize the margin ||2/w|| between the classes.
Training and evaluation
The BERT model is fine-tuned on our dataset and its output embeddings are used as input features for the SVM classifier. The model is evaluated using metrics such as accuracy, precision, recall and F1-score.

Where, TP is true positives, TN is true negatives, FP is false positives, FN is false negatives.
The hybrid approach significantly improves the accuracy of fake news detection compared to traditional methods. The fine-tuned BERT model, when combined with an SVM classifier, achieves higher precision and recall rates, demonstrating its effectiveness in capturing the nuanced context of language used in fake news [5].
LIAR dataset performance
• Accuracy: 85.6%
• Precision: 84.2%
• Recall**: 86.4%
• F1-score: 85.3%
FA-KES dataset performance
• Accuracy: 88.1%
• Precision: 87.5%
• Recall: 88.7%
• F1-score: 88.1%
Fake news net dataset performance
• Accuracy: 90.2%
• Precision: 89.8%
• Recall: 90.5%
• F1-Score: 90.1%
The integration of advanced NLP techniques, particularly transformer models, with traditional machine learning algorithms, provides a robust solution for fake news detection. The ability of models like BERT to understand the context and semantics of language plays a crucial role in distinguishing between true and false information [6].
This results show that the hybrid approach not only improves accuracy but also enhances other evaluation metrics, such as precision and recall. This indicates that the model is effective in identifying both fake news and true news, reducing the number of false positives and false negatives.
The current study presents a promising approach to enhancing fake news detection using advanced NLP techniques. However, there are several avenues for future research and development to further improve the efficacy and robustness of these systems. The following points outline potential directions for future work [7].
Dataset expansion and diversification
Larger and more diverse datasets: Future work should focus on expanding the size and diversity of the datasets used for training and evaluation. Current datasets like LIAR, FA-KES, and fake news net provide a solid foundation, but incorporating more extensive and varied sources of data will improve model generalization and robustness.
Multilingual and cross-cultural data: Expanding the datasets to include multilingual and cross-cultural news articles can enhance the model’s ability to detect fake news across different languages and cultural contexts. This can be particularly useful in global contexts where misinformation transcends linguistic boundaries [8].
Real-time detection systems
Streaming data integration: Developing systems capable of processing streaming data in real-time can provide immediate feedback on the veracity of news articles. This involves integrating the model with social media platforms and news websites to monitor and evaluate the credibility of content as it is published.
Scalability and efficiency: Improving the scalability and computational efficiency of the models is crucial for real-time applications. This can involve optimizing the model architecture and employing techniques such as model pruning and quantization to reduce computational overhead without sacrificing accuracy.
Enhancing model interpretability
Explainable AI techniques: Incorporating explainable AI techniques can help understand the decision-making process of the model. This involves developing methods to visualize and interpret the features and patterns used by the model to classify news articles. This can build trust and transparency, particularly in high-stakes applications [9].
User-friendly interfaces: Creating user-friendly interfaces that provide clear and concise explanations of why a particular news article was classified as fake or real can help users make informed decisions. These interfaces can display key indicators, such as source credibility, linguistic features and social context.
Cross-domain application
Misinformation detection in social media: Applying the model to detect misinformation in social media posts can extend its utility beyond news articles. Social media platforms are significant sources of misinformation and extending fake news detection techniques to these platforms can help mitigate the spread of false information.
Product reviews and online forums: Extending the application of the model to other domains, such as detecting fake reviews on ecommerce platforms and misinformation in online forums, can further demonstrate its versatility and effectiveness.
Advanced NLP techniques
Exploring other transformer architectures: Investigating the performance of other advanced transformer architectures, such as RoBERTa, XLNet and T5, can provide insights into their efficacy for fake news detection. Each of these models has unique strengths that can potentially enhance detection accuracy.
Multimodal approaches: Incorporating multimodal approaches that combine text with other forms of data, such as images and videos, can provide a more comprehensive solution for fake news detection. For example, integrating image recognition and video analysis with text analysis can improve the model's ability to detect deep fakes and other forms of visual misinformation.
Robustness and adversarial resilience
Adversarial training: Implementing adversarial training techniques can make the models more resilient to attempts to evade detection. This involves training the model with adversarial examples designed to deceive the classifier, thereby enhancing its ability to recognize and counteract such tactics.
Continual learning: Developing models that can continually learn and adapt to new patterns of misinformation can maintain high accuracy over time. This involves creating systems that can update their knowledge base and retrain themselves as new data becomes available.
Ethical considerations and bias mitigation
Bias detection and mitigation: Ensuring that the models are free from biases related to race, gender, political orientation, and other factors is crucial. Future work should focus on developing techniques to detect and mitigate such biases, ensuring fair and unbiased detection of fake news.
Ethical frameworks: Establishing ethical frameworks and guidelines for the deployment and use of fake news detection systems can help address concerns related to privacy, consent, and potential misuse. Engaging with policymakers, ethicists and other stakeholders can ensure that these systems are used responsibly and ethically.
Collaboration and open research
Collaborative efforts: Encouraging collaboration between researchers, industry professionals and policymakers can foster the development of more effective fake news detection systems. Sharing datasets, models and findings can accelerate progress and ensure that solutions are aligned with real-world needs.
Open-source initiatives: Supporting open-source initiatives can democratize access to advanced fake news detection tools. Making datasets, code and models publicly available can enable a broader community to contribute to and benefit from this research.
Finally, the future of fake news detection lies in the continuous improvement and innovation of NLP techniques. By addressing the outlined areas, researchers and practitioners can develop more accurate, robust and ethical systems capable of effectively combating the spread of misinformation.
This paper presents an effective method for enhancing fake news detection accuracy by leveraging advanced NLP techniques. The hybrid approach of combining BERT with an SVM classifier shows promising results, outperforming traditional methods. Future work may focus on further optimizing these models and exploring other transformer architectures for improved performance.
Dataset expansion: Incorporate more diverse and larger datasets to train the model further and improve its generalization capabilities.
Real-time implementation: Develop real-time fake news detection systems to provide immediate feedback on the veracity of news articles.
Cross-domain application: Apply the model to other domains, such as misinformation detection in social media posts and product reviews.
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
Received: 29-Jul-2024, Manuscript No. IJIRSET-24-143726; Editor assigned: 31-Jul-2024, Pre QC No. IJIRSET-24-143726 (PQ); Reviewed: 14-Aug-2024, QC No. IJIRSET-24-143726; Revised: 13-Jan-2025, Manuscript No. IJIRSET-24-143726 (R); Published: 20-Jan-2025, DOI: 10.35248/IJIRSET.25.6(1).002
Copyright: © 2025 Benya JA, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
